





In previous articles we demonstrated methods of controlling pod placement on specific nodes, check it out :
- Controlling Kubernetes Pod Placement: Labels and Selectors – Overriding Default Scheduling (Part 1)
- Controlling Kubernetes Pod Placement: Taints & Toleration – Overriding Default Scheduling (Part 2)
- Controlling Kubernetes Pod Placement: Node Selector & Affinity – Overriding Default Scheduling (Part 3)
This article is to show you how to define resource requirements or constraints for your pods also we will check the Daemon Set as well
Resource Requirements and Limits
resource requirements allow you to specify the minimum (requests) and maximum (limits) CPU and memory that a container needs to run.
This feature helps Kubernetes allocate resources efficiently, ensuring that critical applications have enough resources while preventing any single container from consuming too much.
How to specify requests “minimum” and limits ” maximum” resources for a specific pod ? lets have an example.
We have a pod that will not be placed on a node unless there is minimum 512 MB memory and 0.25 CPU cores and maximum 1 GB memory with 0.5 CPU core.
so we define this requests and limits in pod definition file or deployment file as below
apiVersion: v1
kind: Pod
metadata:
name: resource-limited-pod
spec:
containers:
- name: example-container
image: nginx
resources:
requests:
memory: "512Mi"
cpu: "250m"
limits:
memory: "1Gi"
cpu: "500m"
ports:
- containerPort: 80As we knew from the first article of that series , the Schedular is doing the two main steps, filtering the nodes to ignore placing pod on the nodes which haven’t enough resources then rank the remaining from ranking based on priority mechanism. I recommend to read the first article to see how it Schedular works if you didn’t
Controlling Kubernetes Pod Placement: Labels and Selectors – Overriding Default Scheduling (Part 1)
What if there is no enough resources in any of cluster nodes ?
If there is no sufficient resources in any nodes, the Schedular holds scheduling pods and it will be in pending state and you will see the reason like below

What happen if the pods trying to exceed the limit beyond its specified limit ?
For the CPU it will not exceed the specified limit but for memory it is not!
the pod can use more memory than its limit and if the pod is trying to exceed the specified limit for memory constantly the pod will be terminated and you will see that the pod will have error in describe command OOM out of memory kill.
Combination of existence of requests and limits in pod definition
combining requests and limits defines how resources are allocated and managed for a container , so lets discuss possible different combination of specifying requests and limits:
- Both Requests and Limits Defined: The container is guaranteed the requested resources and can use up to the specified limit. Kubernetes uses these values for resource allocation, so the container won’t exceed the limit and will always have at least the requested amount.
- Requests Defined, Limits Not Defined:The container is guaranteed the requested resources, but there’s no cap. It can use as much CPU and memory as available on the node, potentially impacting other containers if it grows unexpectedly.
- Limits Defined, Requests Not Defined:No resources are reserved for the container, but it’s covered at the limit. Kubernetes may schedule the container on a node that’s nearly fully allocated, risking instability if resources aren’t actually available when the container starts.
- Neither Requests Nor Limits Defined: The container can use resources freely without guarantees or restrictions. Kubernetes doesn’t reserve specific resources for it, and the container might face CPU throttling or eviction during high load, depending on the node’s available resources.
The only way to free memory if there is a pod exceed it is to kill the pod!
How to ensure that every created pod have some default set of limits ?
A Limit Range in Kubernetes is a policy that allows you to set default resource requests and limits (CPU, memory, and storage) within a namespace.
be attention that any change in default limits and requests will not be forced on the existing running pods but on the new created ones only!
To define a Limit Range , create a new LimitRange definition file as below example
apiVersion: v1
kind: LimitRange
metadata:
name: example-limit-range
namespace: example-namespace
spec:
limits:
- default:
cpu: "500m"
memory: "512Mi"
defaultRequest:
cpu: "250m"
memory: "256Mi"
max:
cpu: "1"
memory: "1Gi"
min:
cpu: "100m"
memory: "128Mi"
type: ContainerExplanation
default: Specifies default values (cpu: 500mandmemory: 512Mi) if requests and limits are not defined in the pod’s container spec.defaultRequest: Sets minimum requests (cpu: 250mandmemory: 256Mi) for containers that don’t specify requests.maxandmin: Define the maximum (cpu: 1andmemory: 1Gi) and minimum (cpu: 100mandmemory: 128Mi) resources for any container in this namespace.
Any way to restrict the total amount of resources that can be consumed by deployed applications on k8s cluster ?
The answer is yes, and it is a different component called Resource Quote
ResourceQuota is a policy that restricts the total amount of compute resources (like CPU, memory, storage, etc.) that a specific namespace can consume. This ensures fair resource distribution across namespaces and prevents any single namespace from monopolizing resources within a cluster.
Here is an example of defining Resource Quote using ResourceQuote definition file
apiVersion: v1
kind: ResourceQuota
metadata:
name: example-resource-quota
namespace: example-namespace
spec:
hard:
requests.cpu: "2" # Max total CPU requested in this namespace
requests.memory: "4Gi" # Max total memory requested in this namespace
limits.cpu: "4" # Max CPU limits in this namespace
limits.memory: "8Gi" # Max memory limits in this namespace
pods: "10" # Max number of pods
persistentvolumeclaims: "5" # Max number of persistent volume claims
configmaps: "20" # Max number of configmaps
services: "5" # Max number of servicesExplanation
requests.cpuandrequests.memory: Define the maximum total CPU and memory requests that can be made across all containers in this namespace.limits.cpuandlimits.memory: Set the maximum allowable CPU and memory limits.pods,persistentvolumeclaims,configmaps,services: Restrict the count of specific Kubernetes objects within the namespace.
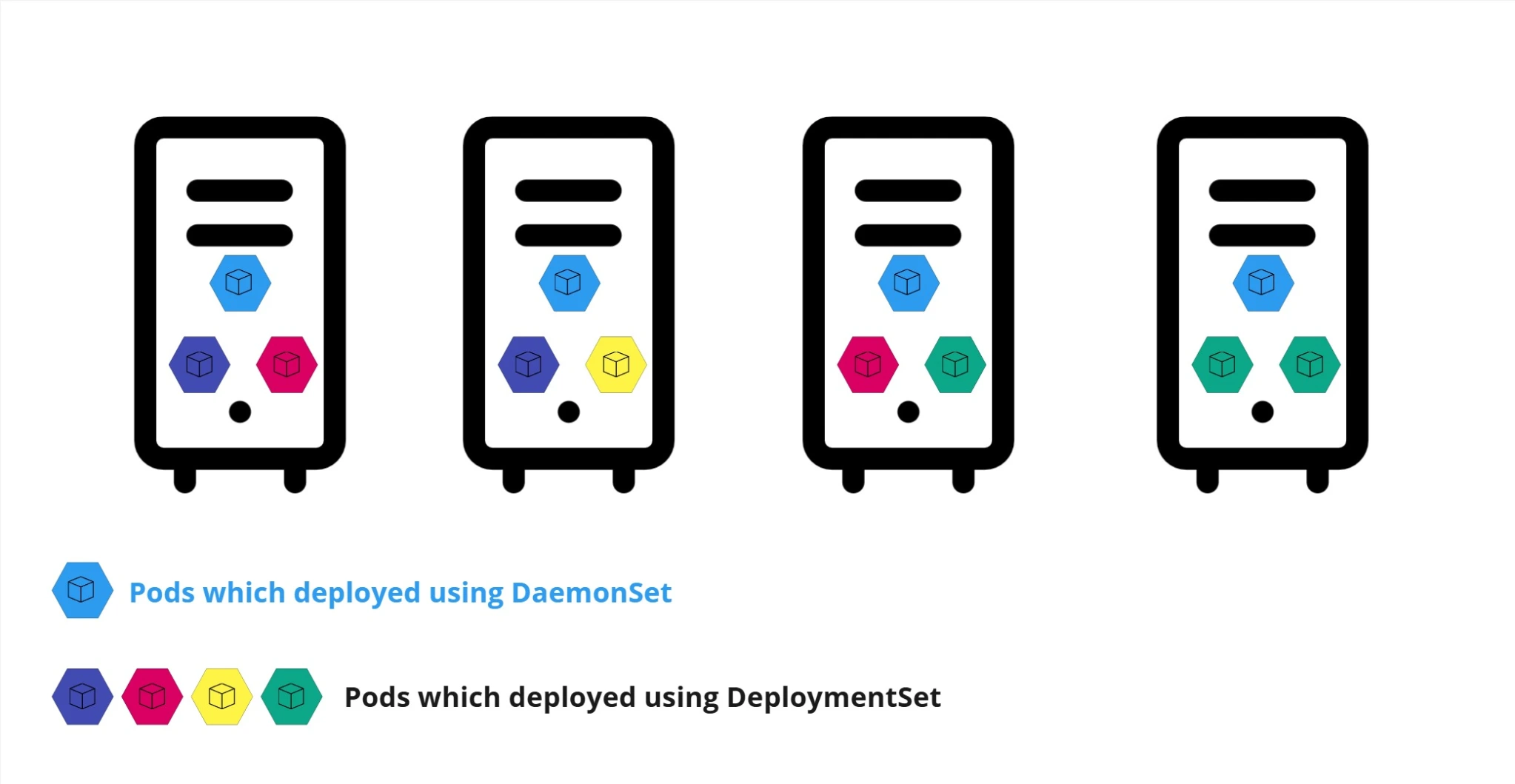
Daemon Sets
Simply Daemon Sets is like replica sets but it runs only one copy of your pod in each node in the cluster!
So Whenever a new node added to the cluster a new copy of the pod added to that node and when a node is removed a pod is automatically removed !
This setup is ideal for tasks that require consistent, node-wide coverage for system management, logging, monitoring, and networking purposes like the mandatory of installing network agents on all nodes in the cluster.
Define a DaemonSet
DaemonSet is like Deployment, you can define it using DaemonSet definition file like below
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: fluentd
namespace: kube-system
spec:
selector:
matchLabels:
app: fluentd
template:
metadata:
labels:
app: fluentd
spec:
containers:
- name: fluentd
image: fluent/fluentd:latest
resources:
limits:
memory: "200Mi"
cpu: "500m"
requests:
memory: "100Mi"
cpu: "200m"
volumeMounts:
- name: varlog
mountPath: /var/log
- name: varlibdockercontainers
mountPath: /var/lib/docker/containers
readOnly: true
volumes:
- name: varlog
hostPath:
path: /var/log
- name: varlibdockercontainers
hostPath:
path: /var/lib/docker/containersExplanation of DaemonSet definition file sections
apiVersionandkind: Specify the resource type (apps/v1andDaemonSet).metadata: Sets metadata, such as the name (fluentd) and namespace (kube-system)- .
spec.selector: Specifies how Kubernetes will match pods managed by the DaemonSet with theapp: fluentdlabel. template: Defines the pod template, which will be used to create pods on each node.metadata.labels: Defines labels for the pod, matching the DaemonSet selector (app: fluentd).containers: Configures the container(s) that the DaemonSet will deploy on each node. Here, it includes a container runningfluentdwith CPU and memory limits.volumeMounts: Mounts directories from the host, sofluentdcan access and forward logs stored on each node.
volumes: Specifies host paths for/var/logand/var/lib/docker/containers, where logs are typically stored on nodes.
Applying the DaemonSet is like any other Kuberentes component through kubectl apply
kubectl apply -f fluentd-daemonset.yamland to view all DaemonSets in all namespaces you can run kubectl get daemonets command
kubectl get daemonsets --all-namespacesor in specific namespace as below
kubectl get daemonsets -n <specific namespace>You can use kubectl describe command with DaemonSet as well get all detailes
kubectl describe daemonset <daemonset-name> -n <namespace>How DaemonSet works ?
Lets ask firstly how to achieve the same placing mechanism for specific pod in all nodes without Daemon Set ?!
Simple by using direct binding method ! you could specify the node name directly in the pod by adding node-name field in the pod definition file or deployment file as below therfore your pod will be placed directly to that node, and this is how DaemonSet works !
apiVersion: v1
kind: Pod
metadata:
name: example-pod
spec:
containers:
- name: nginx
image: nginx
nodeName: node-1So DaemonSet achieve the similar behavior of setting the node name property on the pod be to bypass the schedular but the way DaemonSets work differs slightly from directly setting nodeName !
Conclusion
Through out our journey in these 4 articles we demonstrated different methods to override the default behavior of Kuberents scheduling therefore you who read these articles knows how to control pod placement in different ways. and the possible combination of some methods together to gain more flexible controls on pod placemenet.
I hope you enjoyed this journey. Thanks for reading !
- Controlling Kubernetes Pod Placement: Labels and Selectors – Overriding Default Scheduling (Part 1)
- Controlling Kubernetes Pod Placement: Taints & Toleration – Overriding Default Scheduling (Part 2)
- Controlling Kubernetes Pod Placement: Node Selector & Affinity – Overriding Default Scheduling (Part 3)
- Controlling Kubernetes Pod Placement: Requirements & Limits and Daemon Sets – Overriding Default Scheduling (Part 4)








