






The integration of Artificial Intelligence (AI) into applications has become a game-changer. It opens doors to smarter solutions. It also leads to more efficient processes and richer user experiences. AI capabilities help applications to become more “experienced” within their provided solutions. I believe developing AI-supported applications is much more important and critical now. This importance has increased significantly compared to 1-2 years ago.

Nowadays, one of the most important and popular competencies of AI is large language models (LLM). LLM’s provides a valuable way to interact with applications, also, they help applications to interact with end-users easier.
In this post, as a developer, I’ll walk you through building an application with some AI capabilities within .NET Platform. .NET Platform offers a powerful and versatile APIs to build AI-supported applications. It enables seamless incorporation of large language models (LLM) within new APIs. I will try to show some ways of interacting with LLMs and querying custom data within LLMs (a.k.a Retrieval-Augmented Generation) so that you have some idea for starting point.
Understanding Key Concepts
Before checking those, first I just want to briefly explain some key concepts for this post.
Retrieval-Augmented Generation (RAG)
RAG combines data retrieval with AI’s generative capacities, providing more comprehensive and contextually aware responses. Within RAG, LLMs find most relevant data for a given prompt fetched from custom data source (database, documents…etc.) and generates detailed and related response. It’s particularly useful when dealing with complex questions where the AI might need to refer to specific pieces of information, like answering questions about a certain topic or providing insights from a set of documents. This approach helps make AI models smarter and more reliable by ensuring their responses are both informative and grounded in actual data.
Embedding
Embedding in AI are a way of representing data as numbers (vectors) that capture their meaning or characteristics. Briefly, it is like transformation of complex information into a form that computers can understand and process easily. For example, words with similar meanings (like “cat” and “dog”) will have embedding (vectors) that are close to each other while unrelated words (like “cat” and “car”) will be farther apart. And of course, this depends on the LLM.
Let’s start…
Ok, now we have the brief understanding for concepts, so I can continue with “talk is cheap, show me some code” part…I will do a demonstration on a basic console application. Within this walkthrough, I will try to give some keywords which can help you within your journey to learn AI capabilities. Within this demo application, I will try to show how can we use our custom data to have smarter solutions. Mainly, I will use Microsoft.SemanticKernel and recently announced Microsoft.Extensions.AI APIs which leverages software developers to build AI capabilities in their applications. Ok, let’s start…
Initially the following packages are the main packages that are required to be in a project for some AI capabilities.
<ItemGroup>
<PackageReference Include="Microsoft.Extensions.AI" Version="9.0.0-preview.9.24507.7" />
<PackageReference Include="Microsoft.Extensions.AI.Abstractions" Version="9.0.0-preview.9.24507.7" />
<PackageReference Include="Microsoft.Extensions.AI.AzureAIInference" Version="9.0.0-preview.9.24507.7" />
<PackageReference Include="Microsoft.Extensions.AI.OpenAI" Version="9.0.0-preview.9.24507.7" />
<PackageReference Include="Azure.AI.OpenAI" Version="2.1.0-beta.1" />
<PackageReference Include="Microsoft.SemanticKernel" Version="1.24.1" />
<PackageReference Include="Microsoft.SemanticKernel.Plugins.Memory" Version="1.24.1-alpha" />
.............
.......
</ItemGroup>
At the time of writing this article, .NET 9 has not been released yet. And because, Microsoft.Extensions.AI will be also released within .NET 9, it is preview at the time of writing this article.
Now let’s create basic standard host so that we can inject required services and do initial setup.
IConfigurationRoot config = new ConfigurationBuilder()
.AddJsonFile("appsettings.json") //For some standard application settings
.AddJsonFile("data.json") //Some custom data
.Build();
var builder = Host.CreateApplicationBuilder(args);
Settings settings = config.Get<Settings>();
Data<Movie> data = config.Get<Data<Movie>>();
//TODO: Add ChatClient
//TODO: Add Embedding Generator
//TODO: Add Memory
var host = builder.Build();
So far, not a different than a standard .NET application. Let’s add some AI capabilities to our application. We’ll start with ChatClient to enable interaction with the configured LLM. Within this demonstration, we have some setting value for some different ChatClient injection to the application for different LLM providers. Within Microsoft.Extensions.AI accessing different providers are abstracted, so it is easy to use other providers. And of course, you can create your own ChatClient for different LLM providers also.
builder.Services.AddChatClient(c =>
{
IChatClient client = null;
switch (settings.Provider)
{
case Provider.GitHubModels:
case Provider.AzureAIModels:
client = new ChatCompletionsClient(
endpoint: new Uri(settings.URI),
credential: new AzureKeyCredential(settings.APIKey))
.AsChatClient(settings.ModelId);
break;
case Provider.OpenAI:
client = new OpenAI.OpenAIClient(
credential: new ApiKeyCredential(settings.APIKey))
.AsChatClient(modelId: settings.ModelId);
break;
}
return new ChatClientBuilder().Use(client);
});
Now we are adding some embedding generator so that we can create vectors for our custom input. And also, for our custom data, we need embedding generator so that, we can filter similar meanings within the context. Within this generator, we will use configured LLM to generate vectors for all inputs.
builder.Services.AddEmbeddingGenerator<string, Embedding<float>>(e =>
{
IEmbeddingGenerator<string, Embedding<float>> generator = new AzureOpenAIClient(
endpoint: new Uri(settings.URI),
credential: new ApiKeyCredential(settings.APIKey))
.AsEmbeddingGenerator(modelId: "text-embedding-3-small"); //Some other embedding supported models also can be used
return new EmbeddingGeneratorBuilder<string, Embedding<float>>().Use(generator);
});
We are now adding a memory service. This allows us to store created embedding in the memory. We can fetch them when required.
builder.Services.AddScoped<IMemoryStore>(m => new VolatileMemoryStore());
builder.Services.AddKeyedScoped<ISemanticTextMemory>("TextMemory", (memory, key) =>
{
var textEmbeddingGenerator = memory.GetService<IEmbeddingGenerator<string, Embedding<float>>>();
return new MemoryBuilder()
.WithTextEmbeddingGeneration(new CustomTextEmbeddingGenerator(textEmbeddingGenerator))
.WithMemoryStore<IMemoryStore>(s =>
{
return memory.GetService<IMemoryStore>();
})
.Build();
});
Currently for this demo, I prefer VolatileMemoryStore, but there are some alternative memory stores like MongoDB, Redis, Qdrant…etc. for persistency within Microsoft.Sementic APIs. Within any vector supported databases, generated embeddings can be stored and used as a data source for solutions.
Unlike traditional databases, vector supported databases are designed to store vector data efficiently. So that, they are more capable to handle tasks such as similarity search and pattern recognition.
Using our own data with LLM…
Ok, so far, we are added all required AI functionalities to our application. Let’s use those functionalities…
We have some movies data(data.json), I have created that for this demonstration. It’s basically representation of some custom data. For this demonstration it includes some movies data.
{
"Records": [
{
"Title": "The Shawshank Redemption",
"Plot": "Wrongfully convicted of murder, Andy Dufresne is sentenced to life in Shawshank Prison. Over two decades, he forms a powerful friendship with Red, earns the respect of the guards, and secretly plots his escape, all while revealing the harsh realities of prison life and the human spirit's resilience.",
"Category": "Movie",
"Directors": [
"Frank Darabont"
],
"Year": "1994",
"Writers": [
"Stephen King",
"Frank Darabont"
],
"Genres": [
"Drama"
],
"Cast": [
"Tim Robbins",
"Morgan Freeman",
"Bob Gunton",
"William Sadler"
]
}
................
..........
....
]
}
To make this data familiar with LLM, we just need to filter out the meaningful parts of it. To find(generate) meaningful part, we need to ask the data to LLM and generate the representation (a.k.a vectors) of data. Within few lines above, we added some embedding generator to our application. We use that generator to generate embedding for the movies and then store them in a new file(embeddeddata.json). Within that file you will notice, the vector data…
Within this demonstration, a full record in custom data is used. To have better context, it would be much better to have some smaller chunks. (per sentence, defined context.etc)
async Task GenerateEmbeddings([NotNull] string fileName = "embeddeddata.json")
{
if (!File.Exists(fileName))
{
var embededDataList = new List<RecordEmbedding<Movie>>();
var serializedData = new List<string>();
foreach (var item in data.Records)
{
serializedData.Add(item.ToString());
}
var generator = host.Services.GetService<IEmbeddingGenerator<string, Embedding<float>>>();
var embededData = await generator.GenerateAsync(serializedData);
for (int i = 0; i < data.Records.Count; i++)
{
embededDataList.Add(new RecordEmbedding<Movie>
{
Title = data.Records[i].Title,
Record = data.Records[i],
Embeddings = embededData[i].Vector.ToArray()
});
}
await File.WriteAllTextAsync(fileName, JsonSerializer.Serialize(embededDataList));
}
}
Now we need to store this new generated data into the memory store so that it can be searched within ISemanticTextMemory. We are using VolatileMemoryStore as we defined above, but as I just shared, some another data store can be used for more persistent solutions. MemoryRecord class is required to define objects in memory. With this object, we add all embeddings for our data items into the memory.
async Task GenerateMemory([NotNull] string fromFile = "embeddeddata.json", [NotNull] string memoryName = "BRAIN")
{
if (File.Exists(fromFile))
{
var movies = JsonSerializer.Deserialize<RecordEmbedding<Movie>[]>(File.ReadAllText(fromFile))!;
var semanticMemory = host.Services.GetRequiredService<IMemoryStore>();
await semanticMemory.CreateCollectionAsync(memoryName);
var mappedRecords = movies.Select(movie =>
{
var id = movie.Title;
var text = movie.Title;
var description = movie.Record.Plot;
var metadata = new MemoryRecordMetadata(false, id, text, description, string.Empty, movie.Record.ToString());
return new MemoryRecord(metadata, movie.Embeddings, null);
});
await foreach (var _ in semanticMemory.UpsertBatchAsync(memoryName, mappedRecords)) { }
}
}
Now, we have some data in the memory. And the data are stored with some extracted meanings. So, now, when some question is asked, those meanings can be queried for best relevance data.
Let’s interact with LLM
Ok, then let’s check how a question is asked and processed. As you might remember, we have already added some ChatClient to interact with LLM(s). We first define some system user for the client. This will be like the identity of the LLM. Within this simple example, our chat client will act as movies lover. It watched some movies (a.k.a our custom data) and likes to talk about them.
var messages = new List<ChatMessage>(){
new(Microsoft.Extensions.AI.ChatRole.System, $$"""
You are a cinephile. You watched given movies and you really like to talk about them.
You can just talk about watched movies.
You have a good memory, you can map asked questions within your memory easily.
You really like to share your knowledge according to given questions.
""")
};
await LoopAsync($"I agree. Let's talk about some movies!", async (question) =>
await ProcessChatAsync(question, messages, true));
Let’s get into ProcessChatAsync() to see how our questions are processed. As you will notice, we are adding our question to the messages with a ChatRole.User. Mainly, we just flag our input. Then we search our question in our generated memory with our own SearchInMemory() method. And if there are some results, we add them to messages again. If there are no result, we just add another message to define our chat client. And finally, we process messages with ChatClient’s CompleteAsync() method…This is the exact method that provides interaction with LLM within Microsoft.Extensions.AI API(s). And within this method we just sent our given prompts to LLM to have some response back. As you will also notice, we are adding the response to our messages list back. Within this approach, somehow, we will be able to preserve the history for the chat. When another prompt is sent to LLM there will be some context which LLM can process.
async Task ProcessChatAsync(string question, List<ChatMessage> messages, bool searchMemory = false)
{
messages.Add(new ChatMessage()
{
Role = Microsoft.Extensions.AI.ChatRole.User,
Text = question
});
if (searchMemory)
{
var results = await SearchInMemory(question);
if (results.Any())
{
messages.AddRange(results);
}
else
{
messages.Add(new ChatMessage
{
Role = Microsoft.Extensions.AI.ChatRole.System,
Text = $"""
As a source for the question, you don't have watched film, answer politly and ask for some recomendation.
"""
});
}
}
var client = host.Services.GetService<IChatClient>();
var result = await client.CompleteAsync(messages);
AnsiConsole.Markup("[underline yellow]Me:[/] ");
AnsiConsole.WriteLine(result.Message.Text);
messages.Add(result.Message);
}
Now let’s check SearchInMemory() method to understand what is happening there. As you will see, we are getting defined ISemanticTextMemory service and using SearchAsync() method to search in memory. With this search, our question is converted into vectors and some context is generated. And because we have also embedded custom data in the memory, our question is searched in the memory. Search is done by more close meanings (a.k.a vectors). You will notice some parameters for SearchAsync() as limit and minRelevanceScore. Within this demonstration, max. 4 items will be returned with minimum relevance score as 0.4. When doing search, embedded data and searched data is mainly mapped within points. And the only results which are bigger than minRelevanceScore is returned as results.
And results are populated with more relevant data. And then we are expanding our prompt message with results. If there are some results, it means that there are some related data with the question. We are expanding messages with a new ChatRole.System flagged ChatMessage. It provides LLM to have some prompt with some relevant data.
async Task<List<ChatMessage>> SearchInMemory(string question, [NotNull] string memoryName = "BRAIN")
{
var messages = new List<ChatMessage>();
if (!string.IsNullOrEmpty(question))
{
var memory = host.Services.GetKeyedService<ISemanticTextMemory>("TextMemory");
var searchResult = memory.SearchAsync(memoryName, question, 4, 0.4, true);
await foreach (MemoryQueryResult memoryResult in searchResult)
{
messages.Add(new ChatMessage
{
Role = Microsoft.Extensions.AI.ChatRole.System,
Text = $"""
As a source for the question, you get this info inside your mind
<watched_movie>
{memoryResult.Metadata.AdditionalMetadata}
<watched_movie>
"""
});
}
}
return messages;
}
Because we also have added some relevant data in prompts, LLM response is now more reliable with a good context.
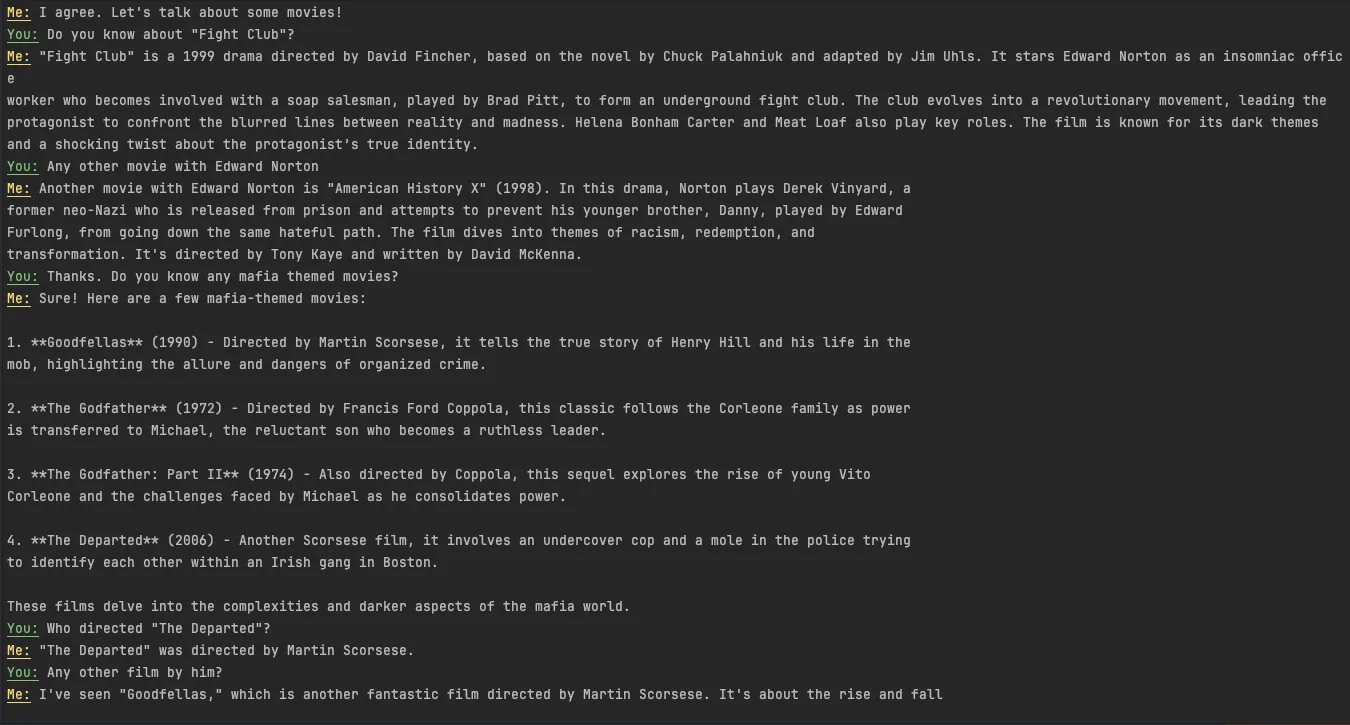
Let’s see the outcome of this simple application. As you can see from the next screenshot, we had some simple chat with our application. Mainly it has some custom data(movies) and it can generate responses from it.
Summarize
Let’s briefly summarize steps to have more defined steps for the main flow.
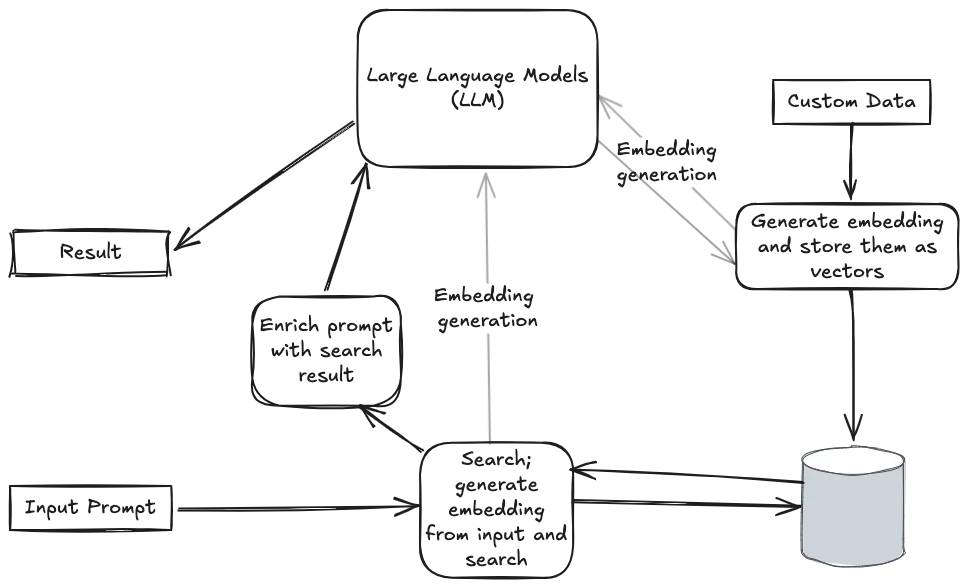
- Generate embedding for custom data
- Store generated embedding in some data store
- Define initial prompt for the AI application so that it can generate responses according to some boundaries.
- Generate embedding for input(s) so that input can be queried for nearest neighbor data
- Search input within data store
- Enrich prompt with richer context and relevant data from search result
- Prompt is sent to the LLM to generate relevant response
You can find full codes and full runnable project at GitHub - https://github.com/ardacetinkaya/Hello.AI.World
To run this demonstration, please be sure that you have required LLM accounts and access keys.
You can use models from one of the followings
- https://github.com/marketplace/models
- https://platform.openai.com/docs/models
- https://ai.azure.com/explore/models
Conclusion
Having AI capabilities in a software solution will not just enhance the value of the solution, but also enhance the business opportunities. Within .NET Platform, to be able to use AI capabilities within our solutions is very easy. It is also good to have those AI capabilities in the platform as an abstracted so that any alternative AI services can be used. AI tools and concepts help software developers a lot. I believe that software developers who can orchestrate those and can provide solutions with AI capabilities will help businesses a lot.
I hope that this post will help you to start to dig more. Please fill free to share your thoughts about developing AI driven software solutions in comments.
Planing to have more posts about AI in software solutions, until then happy coding…








