





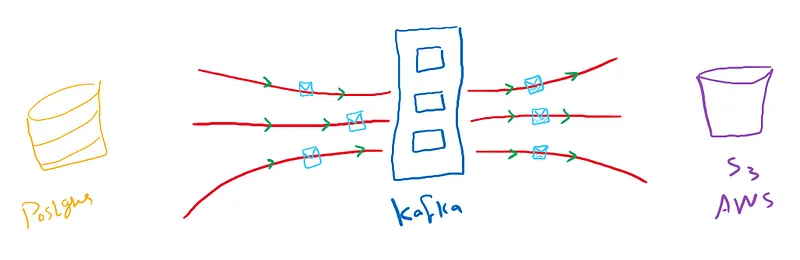
A pipeline that moves data from a source to a sink can be created using Kafka Connect, Postgres (Source), and Amazon S3 (Sink).
Introduction
I am going to demonstrate how to use Kafka connect to build an E2E pipeline using Postgres as the source connector and S3 Bucket as the sink connector
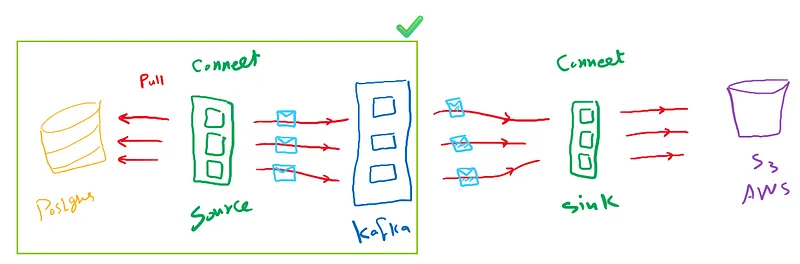
Pipeline Architecture
- Stream Flow

What is Kafka Connect?
Kafka Connect is a tool for scalably and reliably streaming data between Apache Kafka® and other data systems. It makes it simple to quickly define connectors that move large data sets in and out of Kafka.
Kafka Connect can ingest entire databases or collect metrics from all your application servers into Kafka topics, making the data available for stream processing with low latency.
- Stream Flow Using Kafka Connect
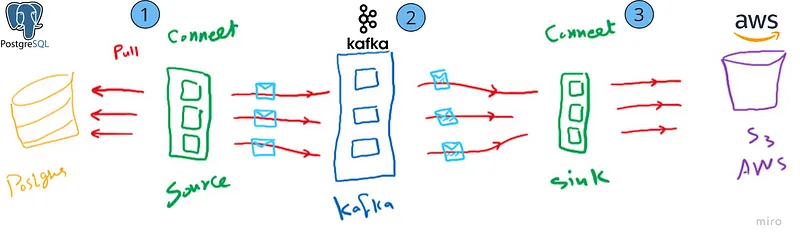
- Source Connector: Jdbc source plugin to fetch data from Postgres database and send it into Kafka topic
- Kafka Brokers /Topics: Hold messages in topics
- Sink Connector: S3 Sink plugin to fetch data from topic
Technical Implementation
- Install Confluent: we are going to use a confluent local instance
- Setup Postgres Source
- Setup S3 Sink
Step 1: Install Confluent
Install confluent community edition on Linux WSL (windows)
. Download Confluent
curl -O https://packages.confluent.io/archive/7.5/confluent-community-7.5.1.tar.gz


. Extract download content

- Configure CONFLUENT_HOME
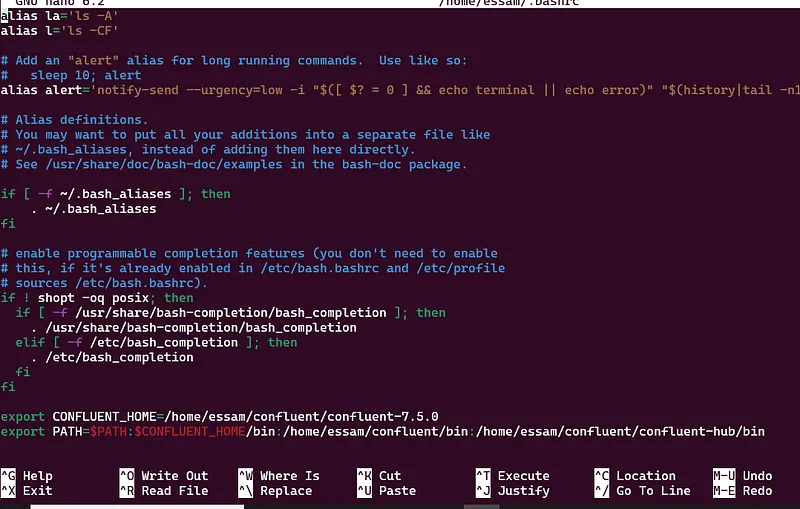
nano ~/.bashrc
# you must run this command on terminal to update env variable
$ source ~/.bashrc
# add those lines to file ~/.bashrc
export CONFLUENT_HOME=your path/confluent/confluent-7.5.1
export PATH=$PATH:$CONFLUENT_HOME/bin

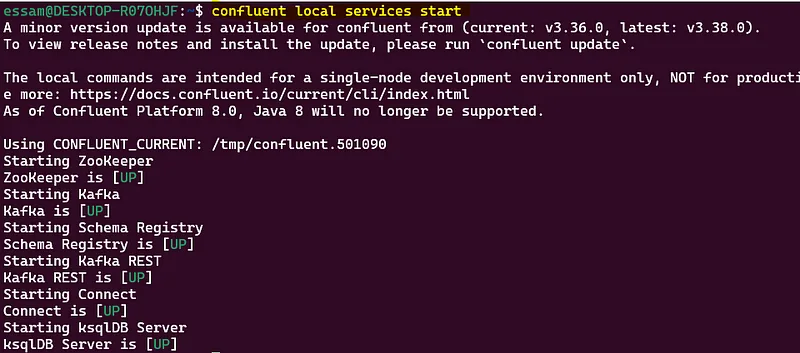
. Start Confluent Locally
confluent local services start
- install confluent-hub client command
wget https://client.hub.confluent.io/confluent-hub-client-latest.tar.gz
export PATH=$PATH:$CONFLUENT_HOME/bin:your_confluent_hub_path/confluent-hub/bin
confluent-hub
Step 2: Setup Postgres Source plugin
- If Postgres is not installed on your Linux system, follow the below links to install and load the data sample
- Install Postgres: https://www.postgresqltutorial.com/postgresql-getting-started/install-postgresql-linux/
- Load data sample: https://www.postgresqltutorial.com/postgresql-getting-started/postgresql-sample-database/
Step 3: Download and Install the JDBC source plugin
confluent-hub install confluentinc/kafka-connect-jdbc:10.7.4
Step 4: Configure Postgres source: create a file with the name source-quickstart-postgres.properties and add below content to it.
name=source-postgres-jdbc
connector.class=io.confluent.connect.jdbc.JdbcSourceConnector
tasks.max=1
connection.url=jdbc:postgresql://localhost:5432/dvdrental??currentSchema=public
mode=bulk
topic.prefix=postgres-jdbc-source-
table.whitelist=city
poll.interval.ms=120000
connection.user=postgres
connection.password=postgres
Step 5: Run the connector
confluent local services connect connector load source-postgres-jdbc --config source-quickstart-postgres.properties
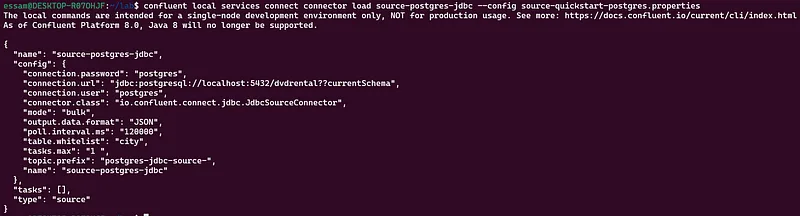
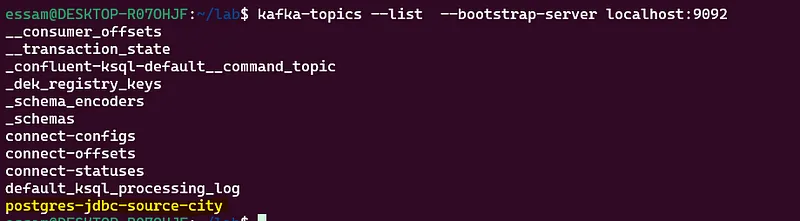
Step 6: Validate Output
validate by checking topic creation
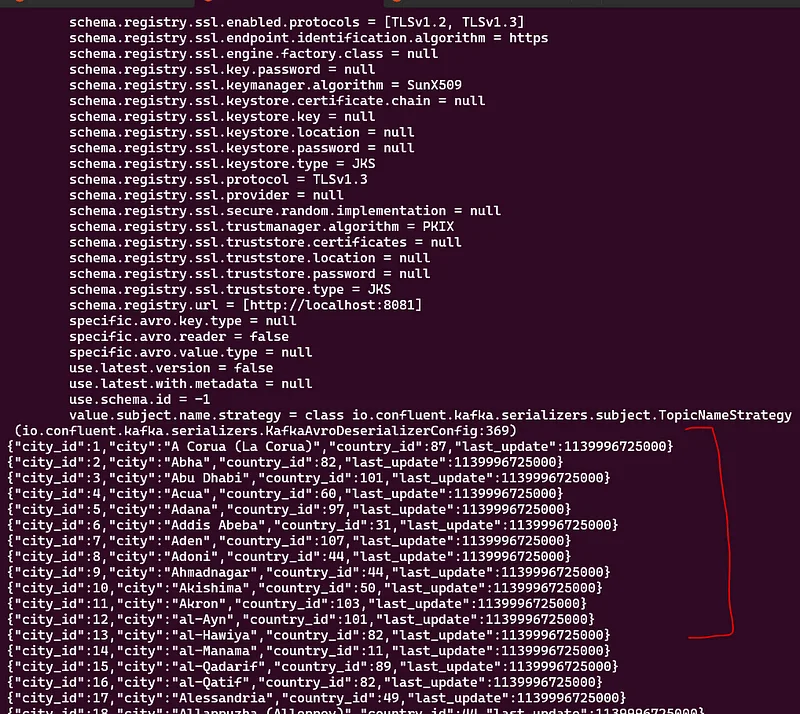
.validate by consuming messages with the local consumer to verify data is loaded
kafka-avro-console-consumer \
--bootstrap-server localhost:9092 \
--property schema.registry.url="http://localhost:8081" \
--topic postgres-jdbc-source-city
Conclusion
We have successfully completed phase one (1) of our pipeline, setting up and executing the Postgres source connector. However, we have only completed part 1 of the process. To finish the pipeline, please proceed to part 2, which involves setting up and configuring the S3 sink.
Please feel free to share your feedback or ask any questions you may have. I am happy to assist you.
References
Kafka Connect | Confluent Documentation
Kafka Connect, an open source component of Apache Kafka, is a framework for connecting Kafka with external systems such…docs.confluent.io








