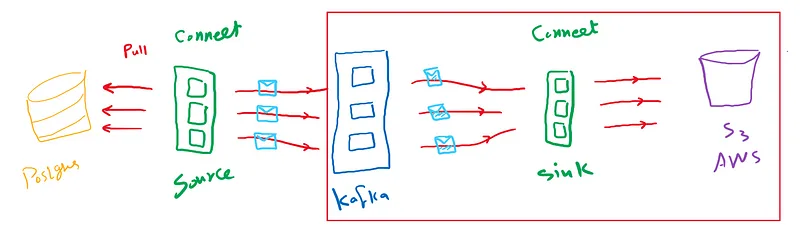
As discussed in Part 1, we will create an end-to-end pipeline that retrieves data from Postgres using a source connector and saves it to AWS S3 using a sink connector.
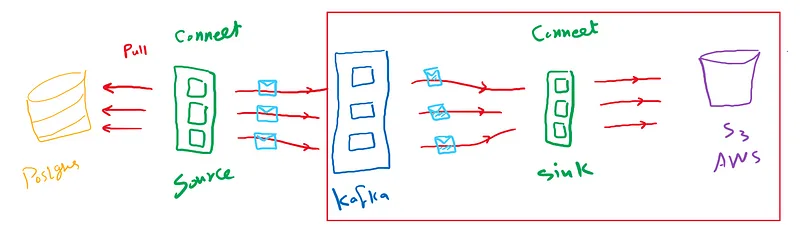
Our main focus now is building the sink connector. As mentioned earlier, we will be using Confluent Connect. The setup should not differ much from native Kafka Connect.
Steps to follow :
Step 1 – Download and install s3 plugin
confluent-hub install confluentinc/kafka-connect-s3:10.5.6
Step 2 – Configure s3 sink properties
. we are going to use the same topic that Postgres uses at Part 1
name=s3-sink
connector.class=io.confluent.connect.s3.S3SinkConnector
tasks.max=1
topics=postgres-jdbc-source-city
s3.region=eu-north-1
s3.bucket.name=confluent-kafka-connect-s3-testing-2023-05
s3.part.size=5242880
flush.size=3
storage.class=io.confluent.connect.s3.storage.S3Storage
format.class=io.confluent.connect.s3.format.avro.AvroFormat
partitioner.class=io.confluent.connect.storage.partitioner.DefaultPartitioner
schema.compatibility=NONE
Important Note : you need to set 2 paramters that are mandatory for authenticating the s3-sink connector to you aws account .
Steps to get access credentials on aws.
- Go to IAM->USERS and create a user
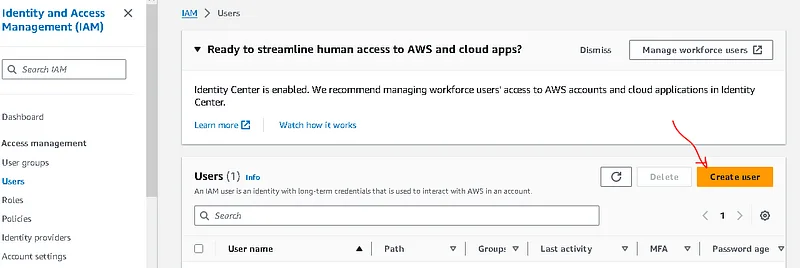
. Add user to group
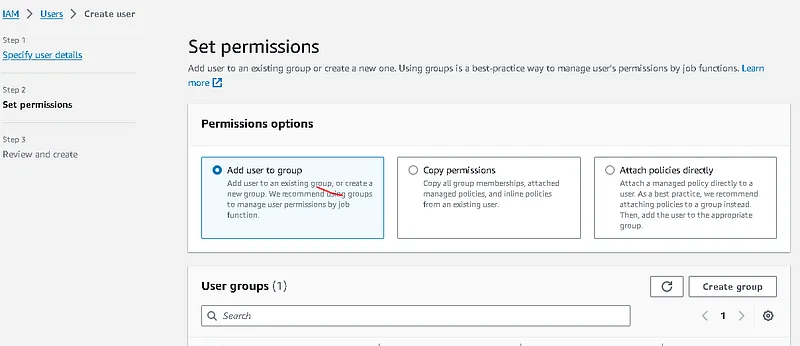
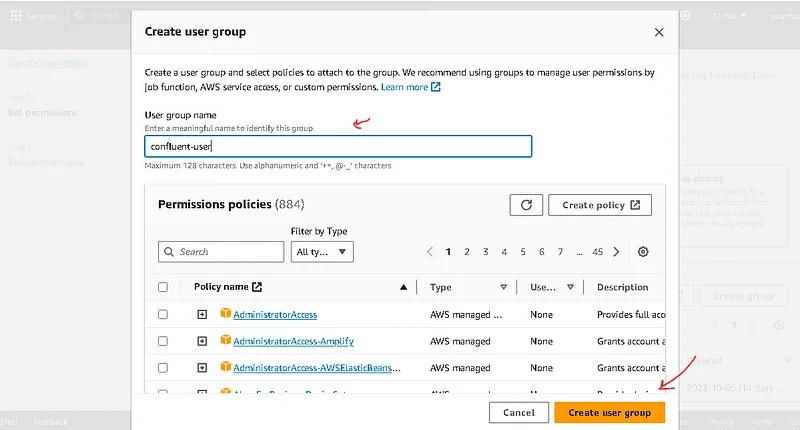
. Create a group and continue
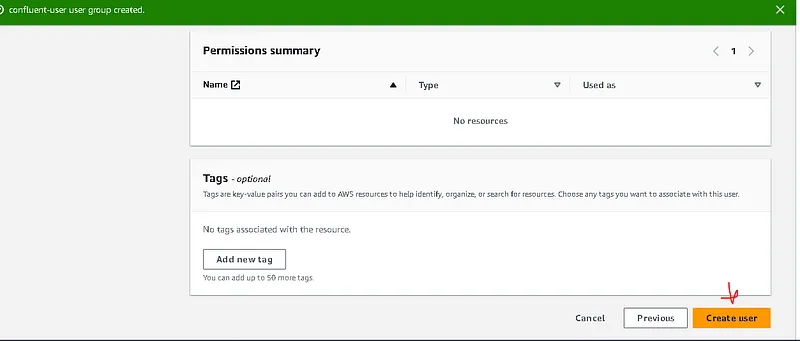
. click create user
. click on your user and go to the security credential then create access key as below
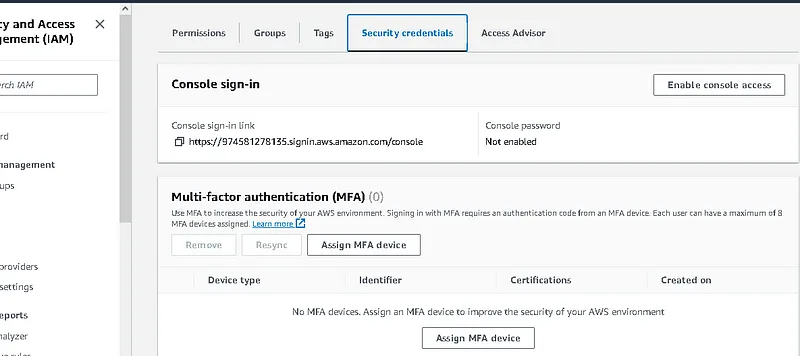
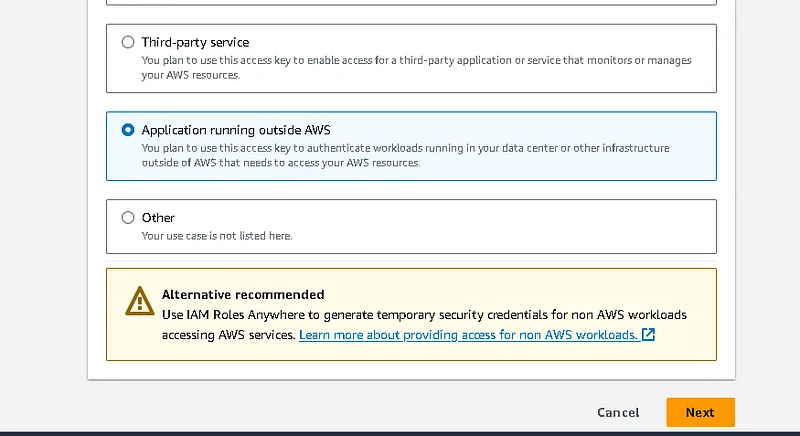
Finally, give a tag name and download it
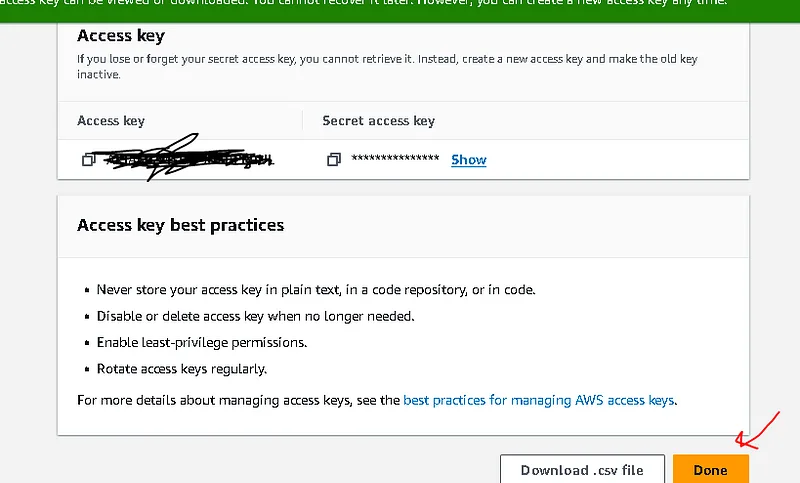
In that file you find 2 properties with values
Access key ID, Secret access key
- You must add them to you environment variable, edit the .bashrc file, and export like below with values
export AWS_ACCESS_KEY_ID=your aws key id
export AWS_SECRET_ACCESS_KEY=your aws acount access secret
source ~/.bashrc
Note: you need to stop and start confluent again to let it see last key changes that you just added
Step 3 – Run the s3 sink connector
confluent local services connect connector load s3-sink --config quickstart-s3.properties
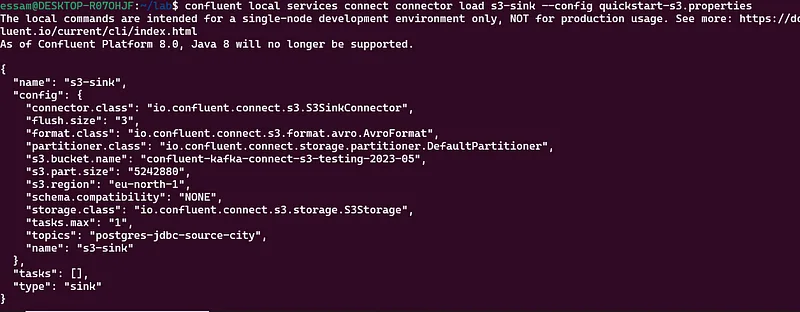
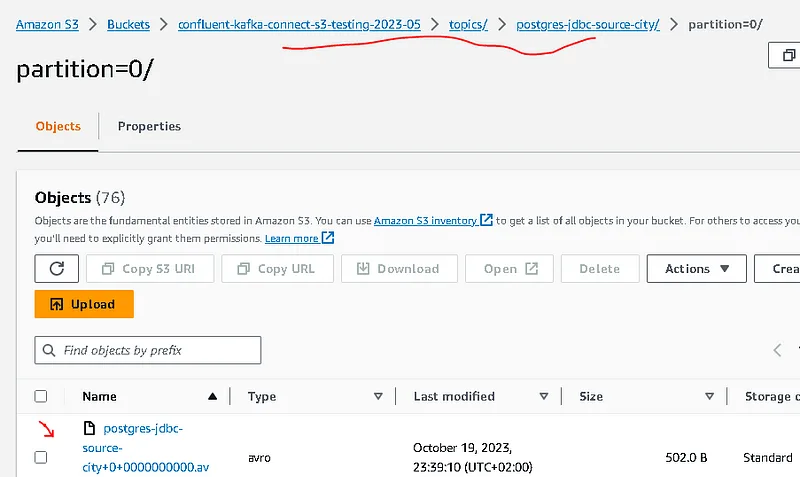
Step 4 – Validate output
check s3 , it should create a path under bucket like → topics/postgres-jdbc-source-city/partition=0/
Conclusion
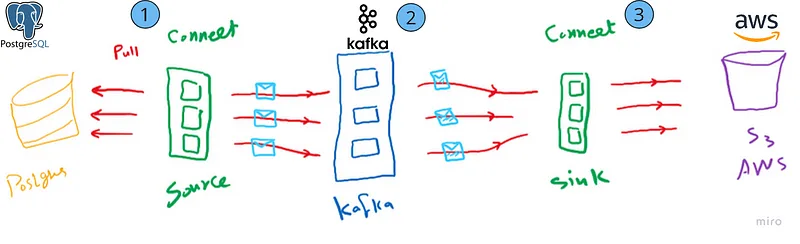
We have successfully completed phase two (2) of our pipeline, setting up and executing the s3 sink connector and being able to consume topic-loaded messages and finally load them into the s3 bucket folder.
Please feel free to share your feedback or ask any questions you may have. I am happy to assist you.
Thanks